Why Are Agents Buying the Same Answer Twice?

Talk to anyone who owns an AI budget right now and you hear the same shift. The easy phase, where a team could trade cost for speed and not think twice, is closing. The question used to be what AI could do. Now it is what it costs to run well, and whether all that spend is buying anything new.
So here is what should bother anyone holding that budget. Somewhere right now a coding agent is scaffolding an auth service that has been built thousands of times before, and a customer-facing agent is answering a support question hundreds of other customers asked in the last hour.
Neither agent can be blamed for it. Most agentic patterns still promote fresh chats, fresh context injection, and fresh reasoning at runtime. Developers pay premium model prices to scaffold the same project and wire up the same login flow. In production, an agent calls an expensive model to reason out an answer another agent instance reasoned out moments earlier.
In an industry that has preached modularity and reuse for decades, why does every problem presented to an agent get treated as novel at runtime?
That question matters because redundant compute shows up later in two places. First, it shows up in the answer to "where did my ROI go?" Second, it sometimes shows up in answer quality, because a system that keeps reasoning about things that are already settled creates more opportunities to drift.
The next stage of maturity for agent systems is simple to describe, even if it takes discipline to implement: if a request is repeated, stable, and expensive to recompute, the system should settle it once and recall it later.
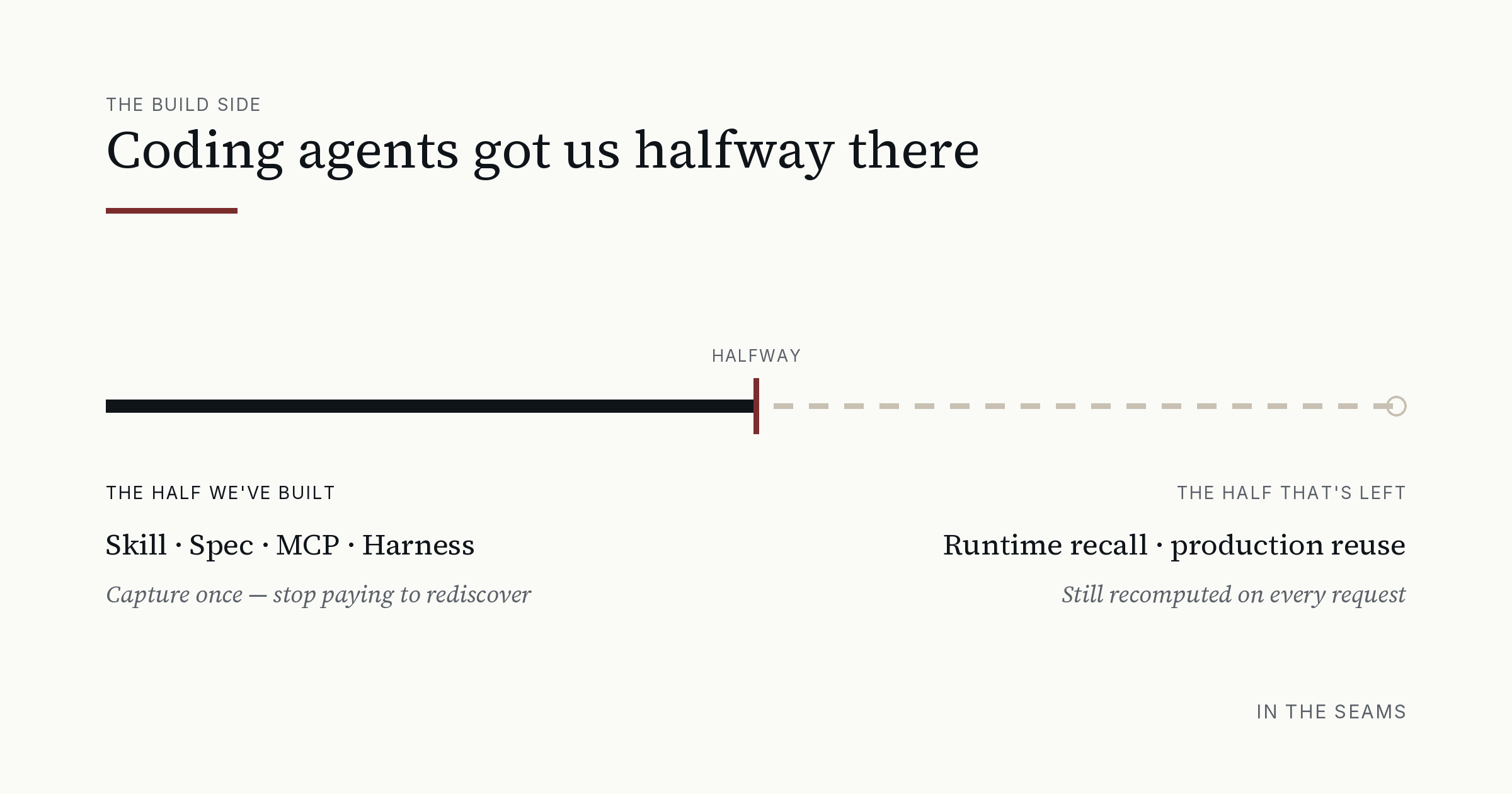
Coding Agents Got Us Halfway There
The last two years have been remarkable. We got agent skills, so a model loads a capability instead of being re-taught it every session. We got MCP, so context reaches an agent through a stable interface. We got spec-driven development, so intent is shaped more explicitly. We got deterministic harness layers that turn probabilistic output into repeatable action.
All of these moves attack the same broad problem. Capture something once so the agent stops paying to rediscover it. A skill settles a capability. A spec settles intent. MCP settles where context lives. A harness settles how execution runs. That is real progress. It made coding agents more predictable and more useful. It also surfaced a design pattern worth carrying forward into the rest of the agent stack. But it did not eliminate the underlying issue. It made prompting more durable, more reusable, and more operationally reliable.
What is durable in a skill is the envelope. It is packaged once, loaded when relevant, disclosed in layers so it does not flood the context window, and the most reliable parts are often the scripts and deterministic components around it. What sits inside that envelope is still natural language interpreted at runtime, and relevance is still a model judgment call. Where that judgment lives turns out to be the whole game, and we will come back to it.
Custom Agents Have The Bigger Economic Problem
The more interesting gap is not on the build side. It is in production.
A coding agent may waste tokens every time a team scaffolds another familiar service. A custom agent can waste tokens every time a user asks another familiar question. The frequency is different, and the economics are harsher.
In the agent projects I’ve built and the teams I advised, I saw a pattern. Consider a standard customer service agent: It takes multiple reasoning steps, context retrievals, and tool calls to resolve a refund-policy question. Twenty minutes later, two hundred subtly different variations of that question arrive. Instead of recognizing the intent, the system executes that same heavy, multi-step reasoning loop two hundred more times. It's paying the full 'agent tax' over and over when a simple recall would do.
That is not a model problem. It is a system design problem.
An agent powered by an expensive model, with no durable memory and no deterministic mechanism to avoid treating every request as novel, is a brilliant junior who never gets more senior. It can think, but it never banks what it already worked out. Watch a customer service agent handle a nuanced edge case like prorating a refund for a bundled subscription. It reads the policy, reasons through the math, and gets the right answer. The next day, a customer asks the exact same edge-case question, and the system burns premium tokens to re-derive the exact same logic.
Durable Memory Is Not A Nice-To-Have
The pattern here is relatively straightforward. When a complex or common query is resolved, the system shouldn't just log the chat. It should extract the final resolution, embed it, and store it in a governed memory and retrieval layer backed by your operational data store. Keep the answer with its embeddings, metadata, provenance, freshness constraints, and whatever policy version is needed to know whether it is still safe to serve. Then make the first step in the workflow cheap and deterministic: before calling the expensive model, check whether the system has already resolved this request closely enough to reuse the answer.
If it has, serve the stored result immediately. That layer should also make it clear where the answer came from, who approved it if approval matters, and when it must be refreshed.
If it has not, escalate to the expensive model, generate the answer, and decide whether that result is durable enough to keep for next time.
The fastest way to reduce inference spend is to call expensive inference less often. But cost is only part of the story. The more common the query, the more likely it is that the best answer should become more settled over time, not less. Popular queries are often the best candidates to move into durable memory, approved response libraries, reusable patterns, or retrieval-backed recall paths.
That is true for support answers. It is true for architectural guidance. It is true for common scaffolds. It is true anywhere the system keeps being asked to re-derive a result that should already exist somewhere outside the model's transient context window.
What To Settle Once
A good kitchen does not cook every dish to order. The prep that is always needed gets done ahead of time; only the things that must be fresh get made the moment they are ordered. A request should be settled once when it is repeated, stable, and expensive to recompute. A refund-policy explanation fits. A standard auth scaffold fits. A common architectural pattern often fits. A well-understood support resolution often fits. In those cases, the system should favor governed recall over fresh reasoning.
That does not mean every fuzzy similarity match should trigger blind reuse. It means the probabilistic judgment gets moved into a place you can inspect and govern. A skill trigger happens inside the reasoning process. A retrieval or recall decision can be externalized. You can set the similarity threshold. You can log the hit rate. You can enforce a freshness window. You can attach confidence rules. You can fall through safely to a more expensive path when the match is not strong enough.
It’s not about making the probability disappear, but ensuring it's not hidden in the middle of a model run. It becomes a control surface.
What To Buy Fresh
Some requests should absolutely be bought fresh. Novel requests belong there. Fast-changing requests belong there. Personal requests belong there. Anything where "close enough" can become wrong in a consequential way belongs there too.
That includes cases where policy may have changed, where the user context materially alters the answer, where time matters, or where the system cannot verify that a prior answer is still safe to reuse. It is the same split I wrote about with one-way and two-way doors in Using Agents, Keeping Agency: some calls you can cheaply walk back, others you have to live with. Recall is safe for two-way-door answers. The one-way-door answers earn fresh reasoning.

The Real Architecture Question
The core question for an agent system is not whether the model can answer the request. It is whether the system should pay for fresh reasoning every time. That is where the next wave of agentic architecture will separate itself. Not in who can attach the most tools or build the cleverest prompt stack, but in who decides what deserves thought, what deserves recall, and what should have been settled already.
If you own the inference bill, that distinction is not theoretical. It is where a meaningful share of the ROI goes. And if you own the user experience, the same distinction shapes quality too. Systems get better when they stop re-arguing settled facts and spend their reasoning budget where judgment is actually required. Thinking is the expensive part. Spend it where the answer is genuinely new, and stop paying full price to buy the same answer twice.
Subscribe
Get new posts delivered to your inbox.